经过了小半年的尝试,终于有了一个我相对满意的模版了~
测试用例模版到底应该用啥?
标准化是体现专业性的捷径,之前推了Excel版用例的标准化。后来组织调整,来到了创新业务的条线,就一直在考虑是否要启用思维导图的方式来作为测试用例的载体。
其实去年在公司的某个创新项目中就进行了一下探索,但是存在一些未解决的问题。现在拿出来说,一方面是为了配合敏捷开发模型中的快速迭代。另一方面我觉得我的模版达到了一个小里程碑。所以聊一下。
目前整个业界对于测试用例的编写载体,基本有3种。
- Excel
- 思维导图
- TestLink、HP ALM等或开源,或收费的测试用例管理平台
TestLink没有试用过,但是HP ALM可以理解为一个加强版的,云端的带有测试用例模板的Excel。从成本(使用、迁移)来说,Excel和思维导图的成本都较低。下面我将这两种形式稍微做下对比:
- Excel
- 优势:
- 可以模板化,从而规范测试用例的编写,进而输出相对合规和高品质的测试用例。
- 可以归档,针对稳定的功能模块,可以相对方便的复用。
- 进度数据很好统计。
- 可以非常直观的展现流程性的内容。
- 劣势:
- 编写耗时较长。
- 文字阅读量大,评审过程非常痛苦。
- 优势:
- 思维导图
- 优势:
- 编写耗时较短。
- 验证点简单直观。
- 劣势:
- 基本没法归档。
- 优势:
可能有朋友会说,思维导图还有“无法统计进度”、“很难模版化”这两个弊病呢。我在当前版本的测试用例模版中一定程度上解决了。
一种用于应对灵活变化的测试用例模版Ver1.0
归档与继承
测试用例在指导测试执行以外,还可能有两个作用归档(已有业务逻辑的传承,可供新人学习使用)、继承(回归测试等测试执行时无需再新写用例)。
其实从现在来看,随着敏捷开发替代了瀑布开发,传统的Full Test, Regression Test(Round X), Sanity Test等相对少了,用例继承的机会也变少了。所以继承变成了伪需求。
而新员工对于老流程的熟悉,其实可以用业务流程总结的文档以及自动化测试用例脚本来熟悉。所以归档的诉求也解决了。
载体
为了避免商业付费和数据安全,试过几款软件,最后选择了百度脑图的本地版DesktopNaotu,可以从github上下载。
模版说明
测试用例模版如下:
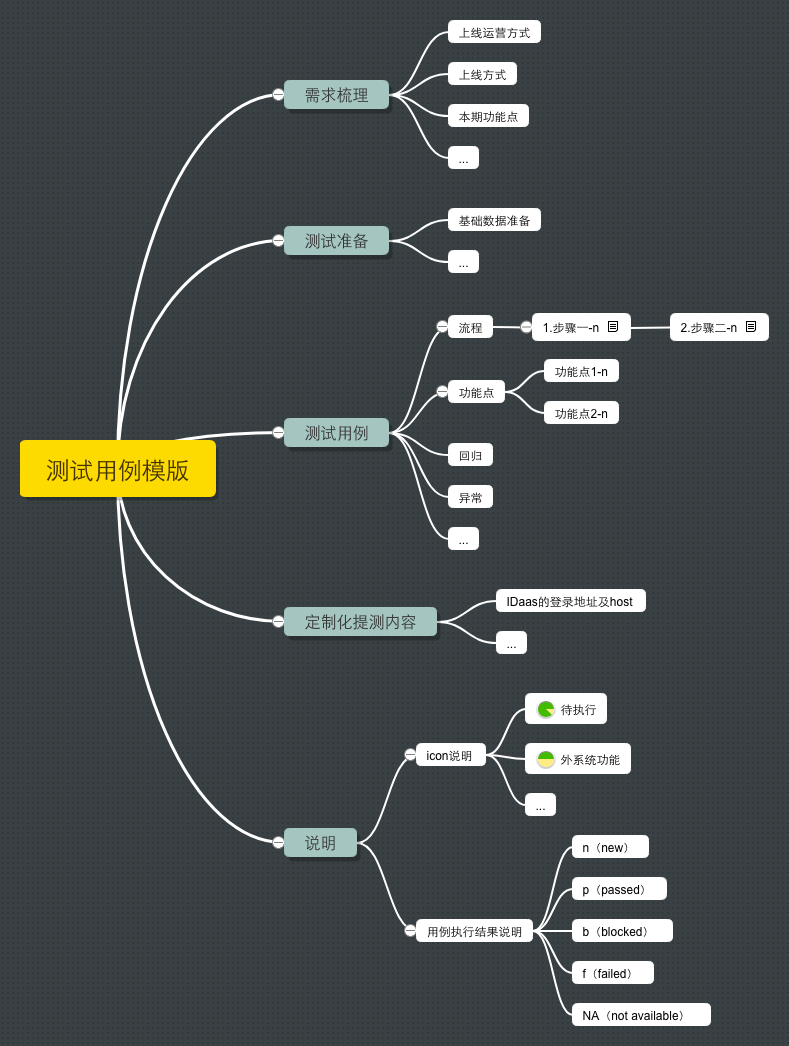
从上面的截图可以看出,测试用例主要分4个板块,需求梳理、测试准备、测试用例、定制化体测内容。
-
需求梳理:主要包含以逻辑的角度拆解需求,以上线过程的角度拆解上线注意事项,以线上运营的角度拆解配置及需求点的合理性。暂时列出了这些,实际可以根据具体的条线或者项目组进行特别设计。 -
测试准备:这部分是在梳理好需求之后,写用例的过程中会得到,在实际测试开始前,需要做哪些准备工作,比如业务主数据的维护,人员权限的配置等。 -
测试用例:测试用例相对复杂,我在后面详细说。 -
定制化体测内容:一般来讲,我们可能有一个提测模版。但是为了减少测试和研发的沟通成本,我将提测内容以定制化的方式体现。就是我们要测试什么,需要研发提供具体的哪些东西,甚至需要一些操作节点的日志关键字。这样做也可以帮助测试梳理逻辑。也能在一定程度上提高研发的提测质量。
测试用例的话,考虑到可读性,单独抽出来,在这里说。分如下几点:
-
流程:主要是体现业务流程的用例,会区分步骤,同时每一个步骤内部还会以Note的形式加入前提条件、步骤描述、预期结果、备注信息、Failed原因等内容,完全是符合传统用例规范的。old fashion but effective -
功能点:为分支流程的单点测试主要列关键点即可。 -
回归:顾名思义,需要做回归的场景。 -
异常:设计的一些异常场景。 -
结果:每一个步骤或者功能点的结果是需要手动标记的,初始是-n;通过的话是-p;被阻塞是-b;有问题(bug)是-f;本次不执行是-NA;注意,千万要按照该标准执行,下面会有一个结果统计工具,是按照该标准统计的。
工具:进度计算器
在DesktopNaotu软件中,右键“测试用例”节点,选择“Export Node”,将节点复制后,粘贴至下面的文本框中,可以计算进度。
请输入用例内容:
-n(new)的数量:
-p(passed)的数量:
-b(blocked)的数量:
-f(failed)的数量:
-NA(not available)的数量:
总数量为; 通过(p+NA)的数量为; 通过率(通过/总数)为
阻塞率(阻塞/总数)为 错误率(错误/总数)为 未执行率(未执行/总数)为